Streaming
(Run this example in Google Colab here)
The Streaming API allows for real-time data transmission during the generation of API responses. By enabling the stream option, responses are sent incrementally, allowing users to begin processing parts of the response as they are received. This is especially useful for applications requiring immediate partial data rather than waiting for a complete response.
Immediate Access: Receive parts of the data as they are generated, which can be useful for displaying real-time results or processing large volumes of data.
Efficiency: Improve the responsiveness of applications by handling data as it arrives, which can be particularly beneficial in time-sensitive scenarios.
We will use Python to show an example:
Dependencies and Imports
You will need to install Prediction Guard into your Python environment.
Now import PredictionGuard, setup your API Key, and create the client.
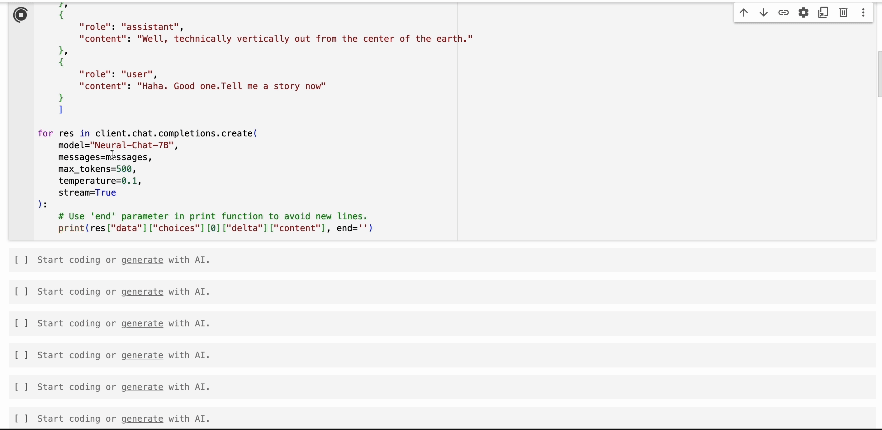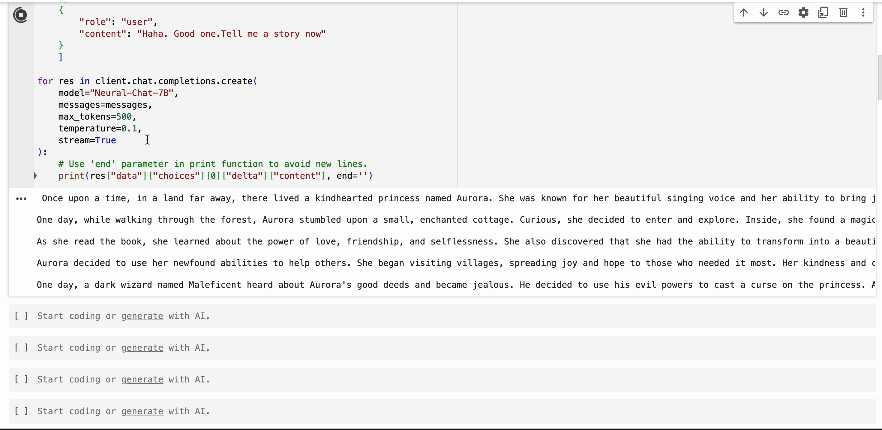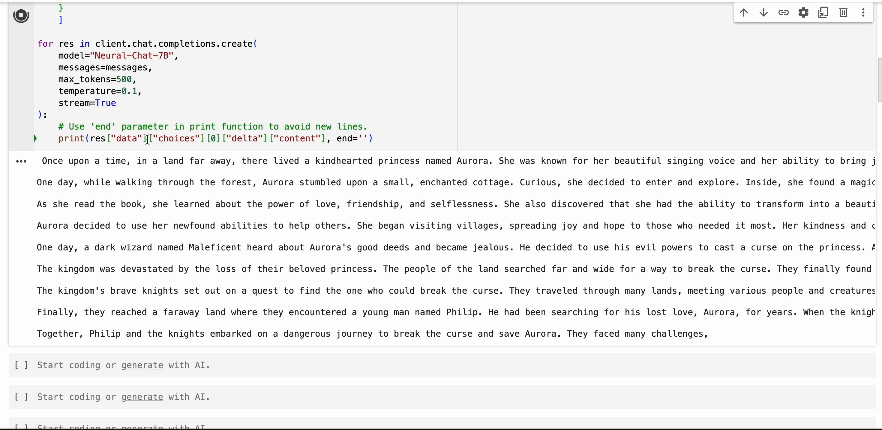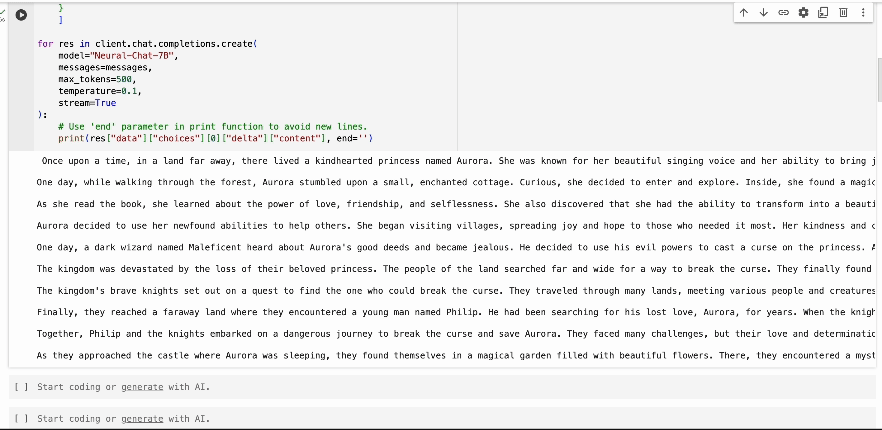
How To Use The Streaming API
To use the streaming capability, set the stream parameter to True in your
API request. Below is an example using the Neural-Chat-7B model:
Using The SDKs
You can also try these examples using the other official SDKs: