Chaining and Retrieval
(Run this example in Google Colab here)
We’ve actually already seen how it can be useful to “chain” various LLM operations together (see other notebooks throughout the Using LLMs sections). In the Hinglish chat example we chained a response generation and then a machine translation using LLMs.
As you solve problems with LLMs, do NOT always think about your task as a single prompt. Decompose your problem into multiple steps. Just like programming which uses multiple functions, classes, etc. LLM integration is a new kind of reasoning engine that you can “program” in a multistep, conditional, control flow sort of fashion.
Further, enterprise LLM applications need reliability, trust, and consistency. Because LLMs only predict probable text, they have no understanding or connection to reality. This produces hallucinations that can be part of a coherent text block but factually (or otherwise) wrong. To deal with this we need to ground on LLM operations with external data.
We will use Python to show an example:
Dependencies and Imports
You will need to install Prediction Guard, LangChain, LanceDB and a few more dependencies in your Python environment.
Now import PredictionGuard and the other dependencies, set up your API Key, and create the client.
Chaining
Let’s say that we are trying to create a response to a user and we want our LLM to follow a variety of rules. We could try to encode all of these instructions into a single prompt. However, as we accumulate more and more instructions the prompt becomes harder and harder for the LLM to follow. Think about an LLM like a child or a high school intern. We want to make things as clear and easy as possible, and complicated instructions don’t do that.
When we run this, at least sometimes, we get bad output because of the complicated instructions:
Rather than try to handle everything in one call to the LLM, let’s decompose our logic into multiple calls that are each simple. We will also add in some non-LLM logic. The chain of processing is:
- Prompt 1 - Determine if the message is a request for code generation.
- Prompt 2 - Q&A prompt to answer based on informational context
- Prompt 3 - A general chat template for when there isn’t an informational question being asked
- Prompt 4 - A code generation prompt
- Question detector - A non-LLM based detection of whether an input in a question or not
Now we can supply the relevant context and options to our response chain and see what we get back:
This should respond with something similar to:
External Knowledge In Prompts, Grounding
We’ve actually already seen external knowledge within our prompts. In the
question and answer example, the context that we pasted in was a
copy of phrasing on the Domino’s website. This “grounds” the prompt with external
knowledge that is current and factual.
The answer returned from this prompting is grounded in the external knowledge we inserted, so we aren’t relying on the LLM to provide the answer with its own probabilities and based on its training data.
Retrieval-Augmented Generation (RAG)
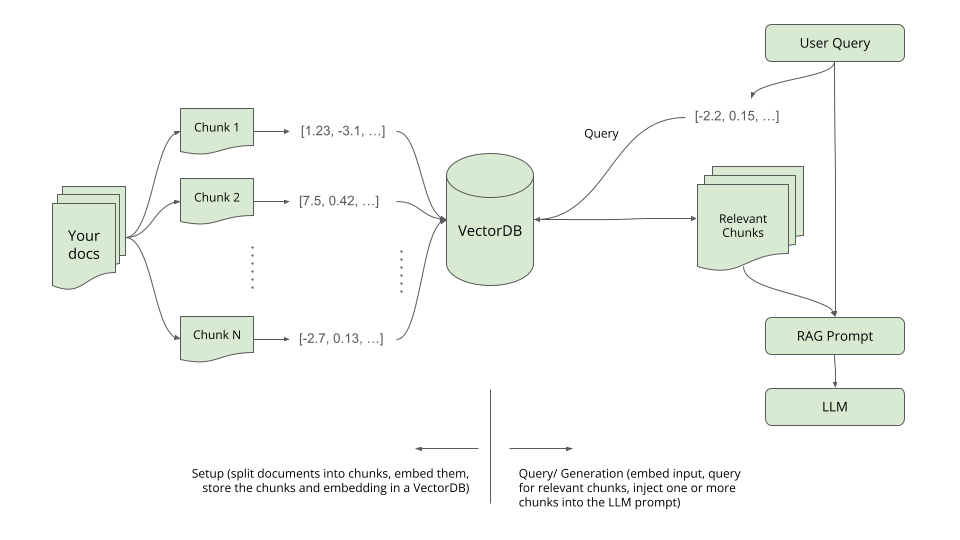
Retrieval-augmented generation (RAG) is an innovative approach that merges the capabilities of large-scale retrieval systems with sequence-to-sequence models to enhance their performance in generating detailed and contextually relevant responses. Instead of relying solely on the knowledge contained within the model’s parameters, RAG allows the model to dynamically retrieve and integrate information from an external database or a set of documents during the generation process. By doing so, it provides a bridge between the vast knowledge stored in external sources and the powerful generation abilities of neural models, enabling more informed, diverse, and context-aware outputs in tasks like question answering, dialogue systems, and more.
This is the text that we will be referencing in our RAG system. I mean, who doesn’t want to know more about the linux kernel. The above code should print out something like the following, which is the text on that website:
Let’s clean things up a bit and split it into smaller chunks (that will fit into our LLM prompts):
Our reference “chunks” for retrieval look like the following:
We will now do a bit more clean up and “embed” these chunks to store them in a Vector Database.
We now have:
- Downloaded our reference data (for eventual retrieval)
- Split that reference data into relevant sized chunks for injection into our prompts
- Embedded those chunks (such that we have a vector that can be used for matching)
- Stored the vectors into the Vector Database (LanceDB in this case)
We can now try matching to text chunks in the database:
This will give a dataframe with a ranking of relevant text chunks by a “distance” metric. The lower the distance, the more semantically relevant the chunk is to the user query.
Now we can create a function that will return an answer to a user query based on the RAG methodology:
This will return something similar to:
Using The SDKs
You can also try these examples using the other official SDKs: